I didn't start with interface sketches. I started by getting in the room.
Laís (PO) and I ran multiple workshop series across both groups. We sat at auditors' desks. Watched them open active cases. Timed where they stopped, hesitated, switched windows, or reached for a Post-it. We used facilitated techniques — 5 Hats analysis, Lightning Decision Jams, dot-voting — not because the methods were magic, but because people who live inside a broken system for years stop seeing the breaks. Structured provocation makes the invisible visible.
By the end of the discovery series, we had catalogued over 60 distinct pain points. Three patterns cut across everything:
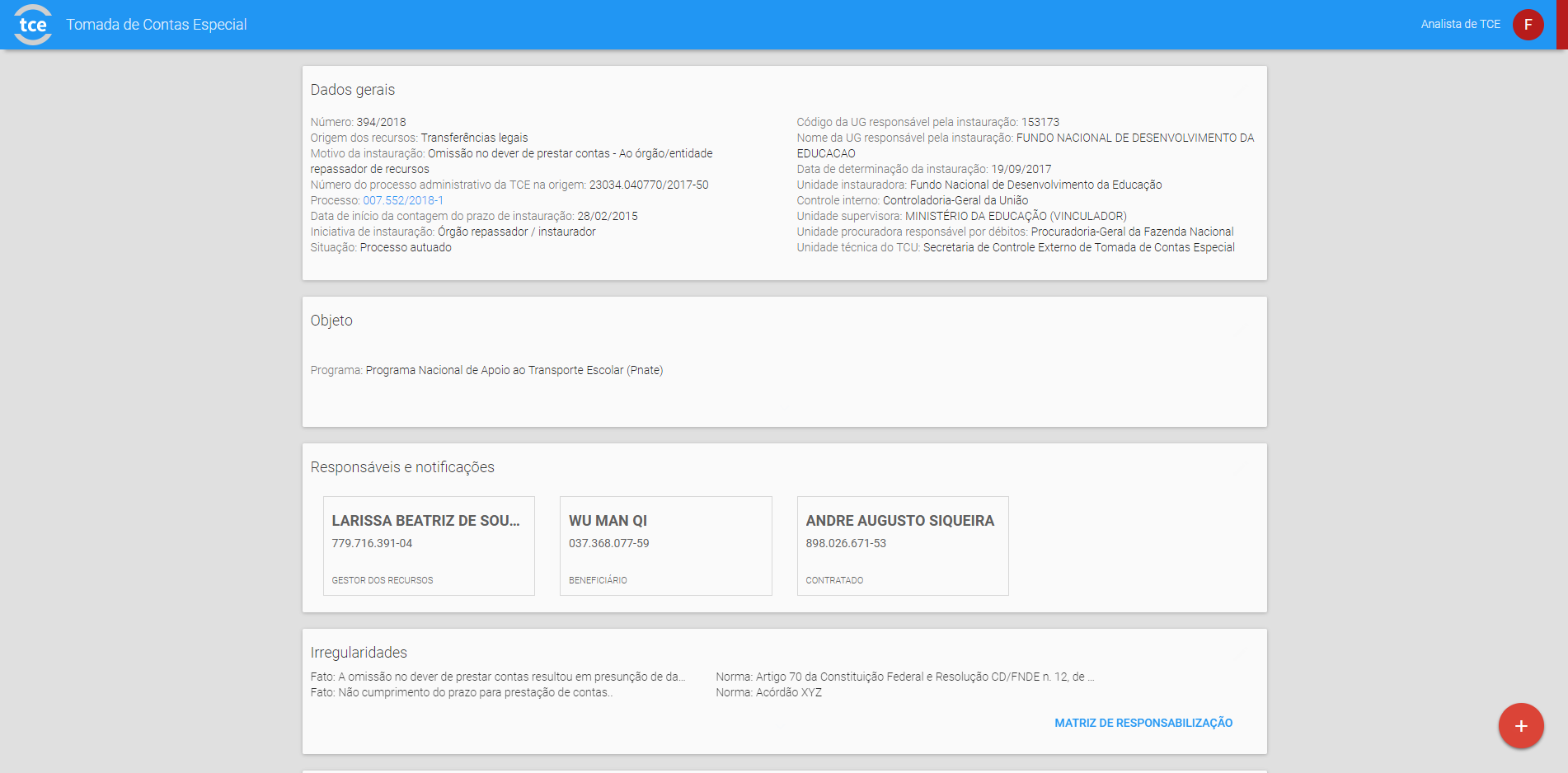
The transcription trap. Auditors spent the majority of writing time copying data they already knew existed in government databases — they just couldn't access it from within their workflow.
The legal citation minefield. Audit Instructions required precise citations to specific articles of multiple federal regulatory frameworks. A wrong article number, even with correct intent, triggered rejection.
The invisible queue. Cases were processed chronologically. A R$20,000 irregularity got the same queue position as a R$25M one.
These three patterns became the real design brief. Every product decision we made traces back to one of them. The workshop process also produced something harder to quantify: by the time we were building prototypes, the auditors were bringing their own live cases to test against. That shift — from skeptical subjects to invested co-designers — is why we hit 100% voluntary adoption at launch.